

Using your AI Calculator
My Little LLM Professor


When LLMs like ChatGPT first emerged and students began using them en masse for homework, AI advocates drew an analogy to the introduction of calculators in schools. They called it a “calculator moment” for AI—just as calculating capabilities in the 1970s and 1980s moved from specialized, high-end computing environments into widespread handheld use, AI was now becoming democratized and accessible to everyone.
Educators were quick to point out how flawed this analogy is. A calculator doesn’t think for you—it simply processes the numbers you’ve already decided to use. The real work happens beforehand: deciding on the method, framing the problem, and knowing what to calculate (How do I solve this? What’s the formula for the volume of an engine cylinder?). Writing, however, is thinking. It’s where ideas take shape, where half-formed notions turn into clarity, and where our understanding deepens. It’s also a source of joy—which is why I’m drafting this by hand, relying on AI grammar checkers only for the final polish.
But, let’s take a minute and actually compare an LLM like ChatGPT to a calculator. Doing so highlights why tools like ChatGPT are so easily misused—and how to get better results from them.
First, calculators only accept numbers—the very thing they’re designed and programmed to handle. Generalized LLMs, like ChatGPT have no such guardrails. You can feed it verbal “calculations” that are far beyond its actual capacity to process accurately.
Second, calculators are bound to the exact inputs you provide. Your trusty HP-10 doesn’t take your numbers and blend them with random figures it scraped from somewhere else. LLMs, on the other hand, can “hallucinate,” confidently inserting information simply because it sounds plausible. It’s as if your financial calculator decided to tack on an extra $10 million because it thought you’d be impressed.
Third, calculators are limited to the functions on their keypads, performing each one in a fixed, well-tested way. LLMs are far less consistent. A recent study showed they often approach the same problem differently each time they’re asked.
And finally, when you give a calculator a nonsensical input—like dividing by zero—it returns an error. Most general-purpose LLMs will instead deliver a confident-sounding answer, often tailored to what they think you want to hear. They can be very sycophantic, reenforcing your own biases. An error message is rare.
So, how do you get good results from ChatGPT or any other LLM when you’re just starting out? You have to be the calculator: supply reliable inputs, instruct it not to pull in outside information, and limit it to tasks you know it can handle. For example, ask it to transform your own ideas or writing into other forms—something well within its strengths—rather than trusting it to generate flawless facts from scratch.
For example, In June, I co-presented a poster at the HCI International 2025 Conference on using AI-generated images to create memorable visual mnemonics by blending familiar concepts—helping humans remember large numbers, such as bitcoin keys, more effectively. Our paper will be published in the conference proceedings, but we also wanted a visually striking summary slide for the program. This was a perfect task for an LLM like ChatGPT or Claude—tools that work best as “word calculators,” transforming existing information into new formats. In this case, I uploaded the paper and entered this prompt:
This paper was accepted to the human computer interaction conference. Using just the information in the paper, create one image for the online poster presentations that is 800x450 and provides concise overview of the work, with clear illustrations and attractive visual design. Please make this design for me.”
And the LLM I was using, Claude, produced this:

The conference allowed for an expanded poster as well. In this case I asked Claude to produce a website (html code) based on the paper. I was able to then take that code and images and upload to a hosting platform (github), and then just printed that out for the expanded poster. This took me less than 5 minutes. You can view the website and inspect the code by clicking here or on the screen shot below.

The next step in our study is to extend these ideas into new areas—for example, using encoding schemes to generate stories capable of representing very large numbers. This time, my colleague Tojin T. Eapen crafted a more complex prompt and ran it through an LLM specialized in writing code, producing a program to begin testing our concepts. It took him less than an hour to get it working relatively well. You can try an early draft by clicking here or on the image below; and if it doesn’t make much sense, don’t worry I will explain in an upcoming post. 😀

Raising Expectations for Academics?
In a perfect world, the widespread availability of these new “calculators” would raise the bar for academic publication. Take our own HCI conference paper as an example—it proposed a methodology but didn’t include an experiment. Today, with the ability to “vibe code” the necessary software for an experiment or “vibe prototype” a working model (more on that soon), why should a paper be accepted without those deliverables?
Shouldn’t AI be pushing research standards higher? In our case, perhaps we should have been expected to go further—maybe even publishing a GitHub repository with working code so others could test our idea. These tools dramatically shorten the research timeline; work that might have taken two years and produced five separate papers could, with AI, be completed in three months and reported in one paper. If we can do more, faster, we should be expected to deliver more—and better—research outputs.
However, my cynical view of academic publishing—and the mess that is the tenure and promotion process—is that we’re heading in the opposite direction. Instead of raising expectations, AI will be used to slice and dice projects into even more papers, each thinner than the last. This isn’t new; even before LLMs gained momentum, the number of academic papers published each year had already been climbing at a dramatic rate.
Scientists are increasingly overwhelmed by the volume of articles being published. Total articles indexed in Scopus and Web of Science have grown exponentially in recent years; in 2022 the article total was approximately ~47% higher than in 2016, which has outpaced the limited growth - if any - in the number of practising scientists.
-From the Abstact to “The strain on scientific publishing” by Mark A. Hanson, Pablo Gómez Barreiro, Paolo Crosetto, and Dan Brockington.
The problem is that more papers don’t necessarily mean more knowledge. When projects are split into the smallest publishable units, the results become fragmented, repetitive, and harder to build upon. AI only supercharges this tendency: drafting is faster, formatting is instant, and “filler” sections can be generated at scale. The current incentive structure doesn’t reward academic risk-taking—so for a tenure-track academic, putting all your eggs into one ambitious paper that might be rejected is simply not a viable career strategy. AI isn’t a catalyst for bolder research—it’s fuel for playing it safe at scale.
While I couldn’t find definitive data on submission rates to academic journals since ChatGPT’s release, I strongly suspect they’ve risen. What we do know is that AI-assisted writing in academic papers is on the rise. A recent study, Mapping the Increasing Use of LLMs in Scientific Papers, showed the dramatic increase in academic writing that most likely has been written by an LLM. .
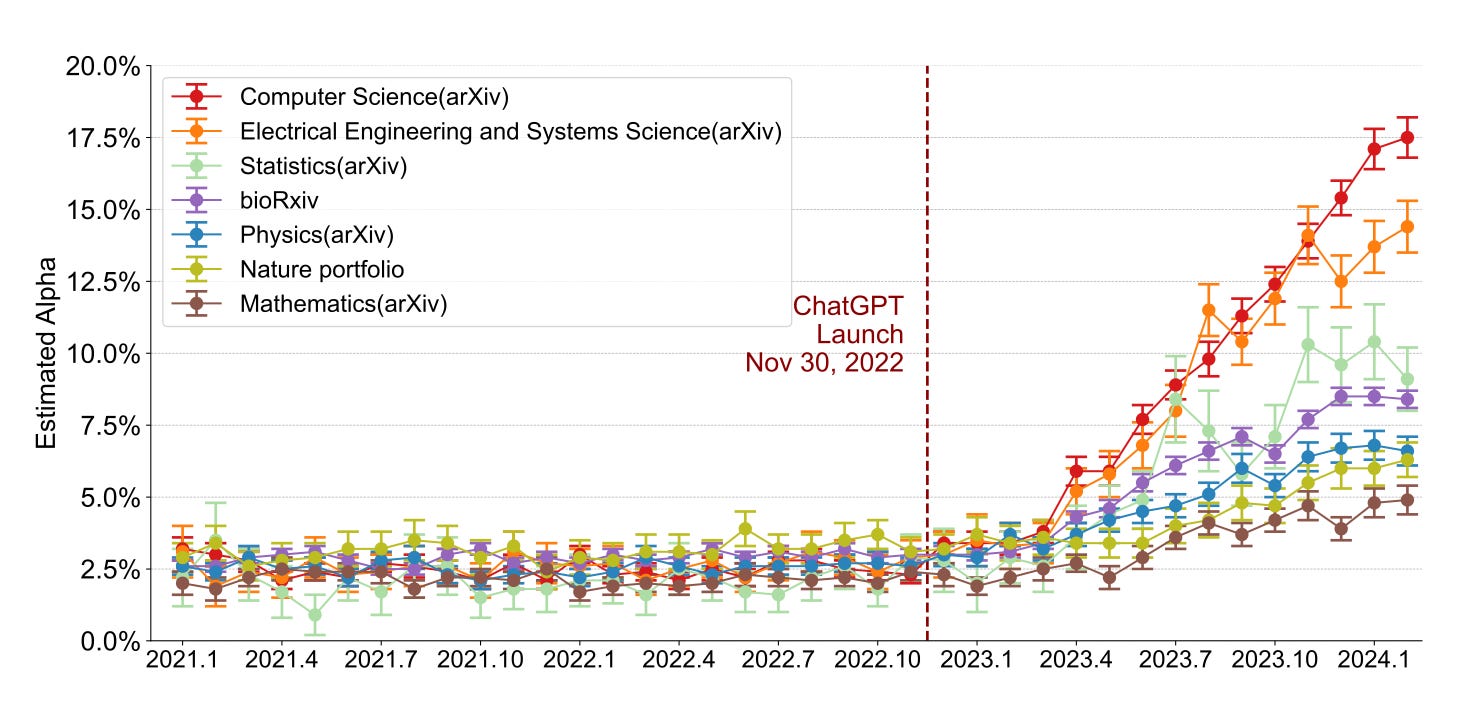
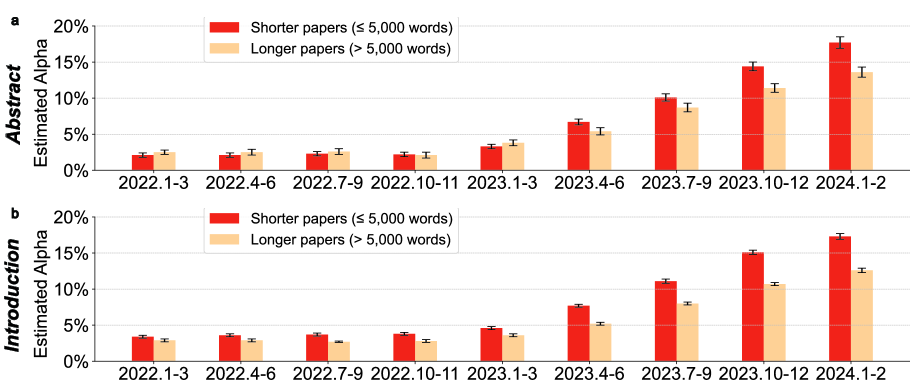
And the same study found evidence that shorter papers have a higher probability of having AI generated text include.
What do you think?
Will the better angels of our writing nature prevail, turning these new “calculators” into tools for sharper thinking and better scholarship—or are we already on the express train to an AI-generated Academic Sloppocalypse?
Drop your verdict in the comments.
My commentary may be republished online or in print under Creative Commons license CC BY-NC-ND 4.0. I ask that you edit only for style or to shorten, provide proper attribution and link to my contact information.
📥Recent Talks, News and Updates
I was interviewed by CHS Faculty Fellow for AI in Teaching, Greg Cox, for a Integrating AI into Teaching series in the School of Health Related Professions.
I was featured as a “Person You Should Know (PYSK)” in the Columbia Business Times in March! This was a lot of fun and you can read the profile here.
I was also profiled in the Boomtown Supplement for the Columbia Missourian in April. You can read it here.
👍 Products I Recommend
Products a card game for workshop ideation and ice breakers (affiliate link). I use this in my workshops and classes regularly.
📆 Upcoming Talks/Classes
I will be presenting “AI Agents: Friend or Foe?” for the Human Resources Association of Central Missouri on September 9th at 8:30 am. Details about the program will be posted here.
Description: AI “agents” are the next step beyond chatbots: digital teammates that set goals, take actions across your apps, and finish real work while you sleep. Prof C will explain—in plain language—how these tireless helpers can streamline HR tasks like onboarding and analytics … and why the same autonomy can create new risks if we’re not careful. Join us to learn simple guardrails for deciding when an AI agent is a friend, when it might become a foe, and how to stay firmly in control.
I will be presenting “AI Strategies” for the Red River Valley Estate Planning Council, in Fargo, North Dakota on November 19. Details will be available here.